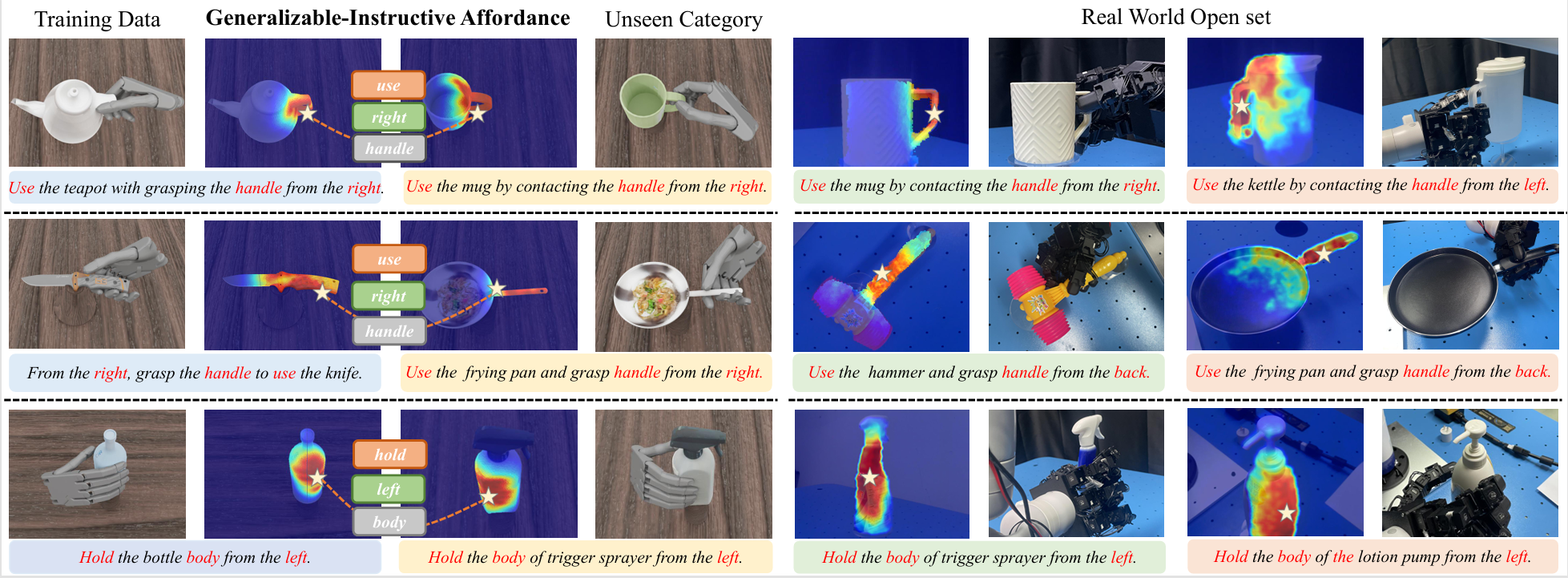
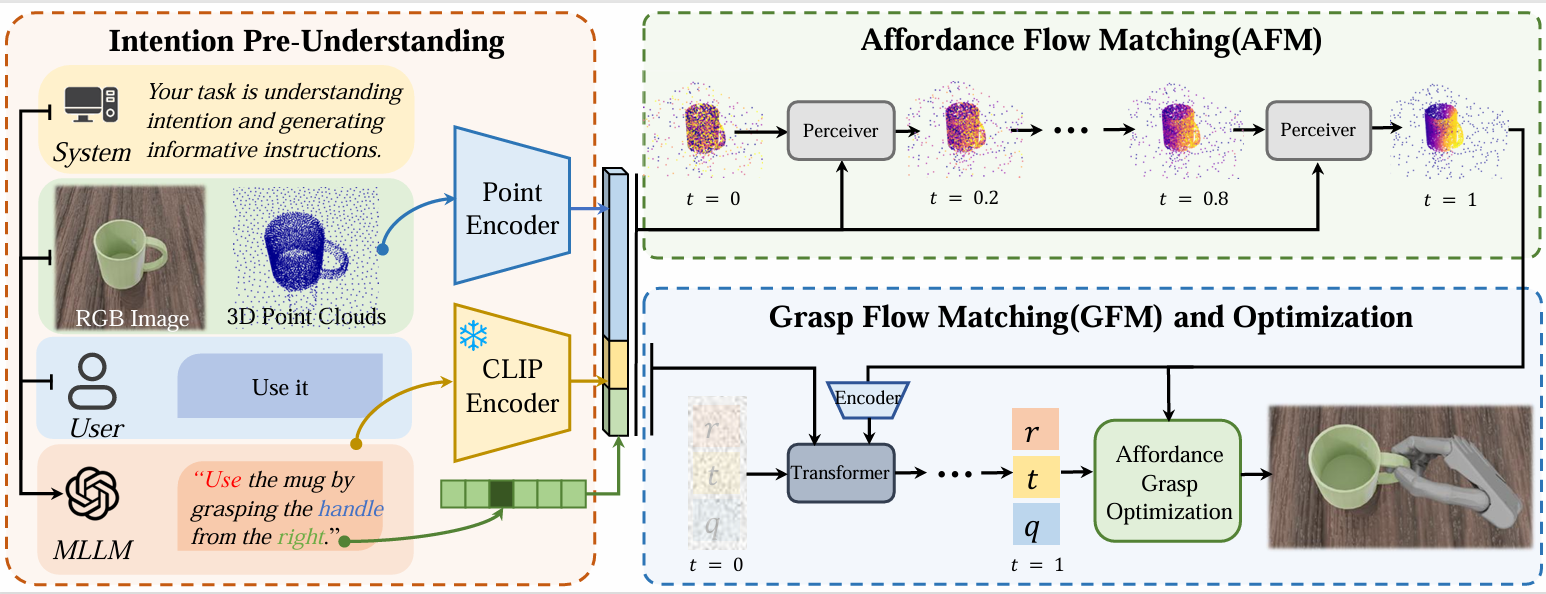
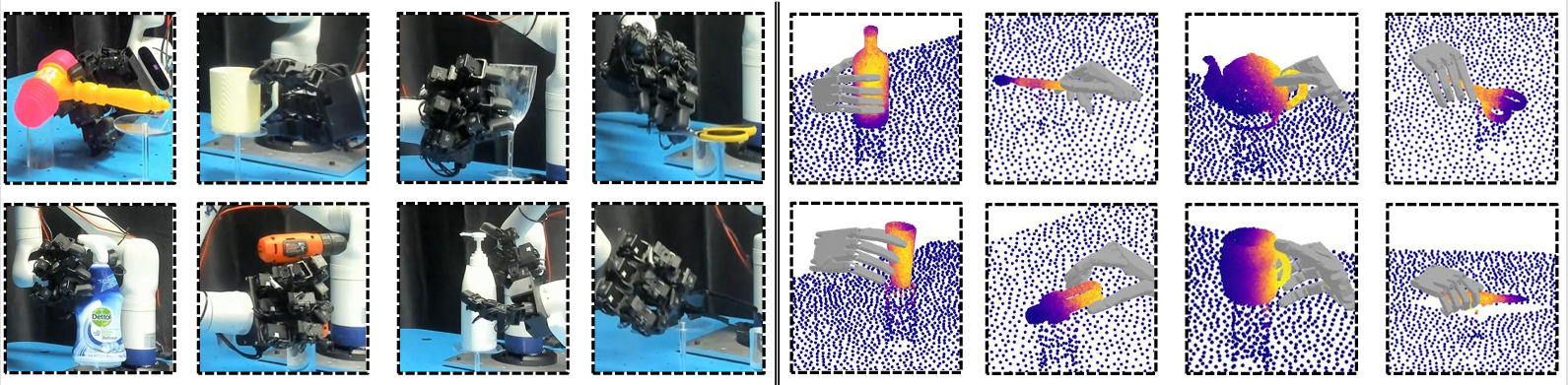
Abstract
Language-guided robot dexterous generation enables robots to grasp and manipulate objects based on human commands. However, previous data-driven methods are hard to understand intention and execute grasping with unseen categories in the open set. In this work, we explore a new task, Open-set Language-guided Dexterous Grasp, and find that the main challenge is the huge gap between high-level human language semantics and low-level robot actions. To solve this problem, we propose an Affordance Dexterous Grasp (AffordDexGrasp) framework, with the insight of bridging the gap with a new generalizable-instructive affordance representation. This affordance can generalize to unseen categories by leveraging the object's local structure and category-agnostic semantic attributes, thereby effectively guiding dexterous grasp generation. Built upon the affordance, our framework introduces Affordacne Flow Matching (AFM) for affordance generation with language as input, and Grasp Flow Matching (GFM) for generating dexterous grasp with affordance as input. To evaluate our framework, we build an open-set table-top language-guided dexterous grasp dataset. Extensive experiments in the simulation and real worlds show that our framework surpasses all previous methods in open-set generalization.