ReferDINO
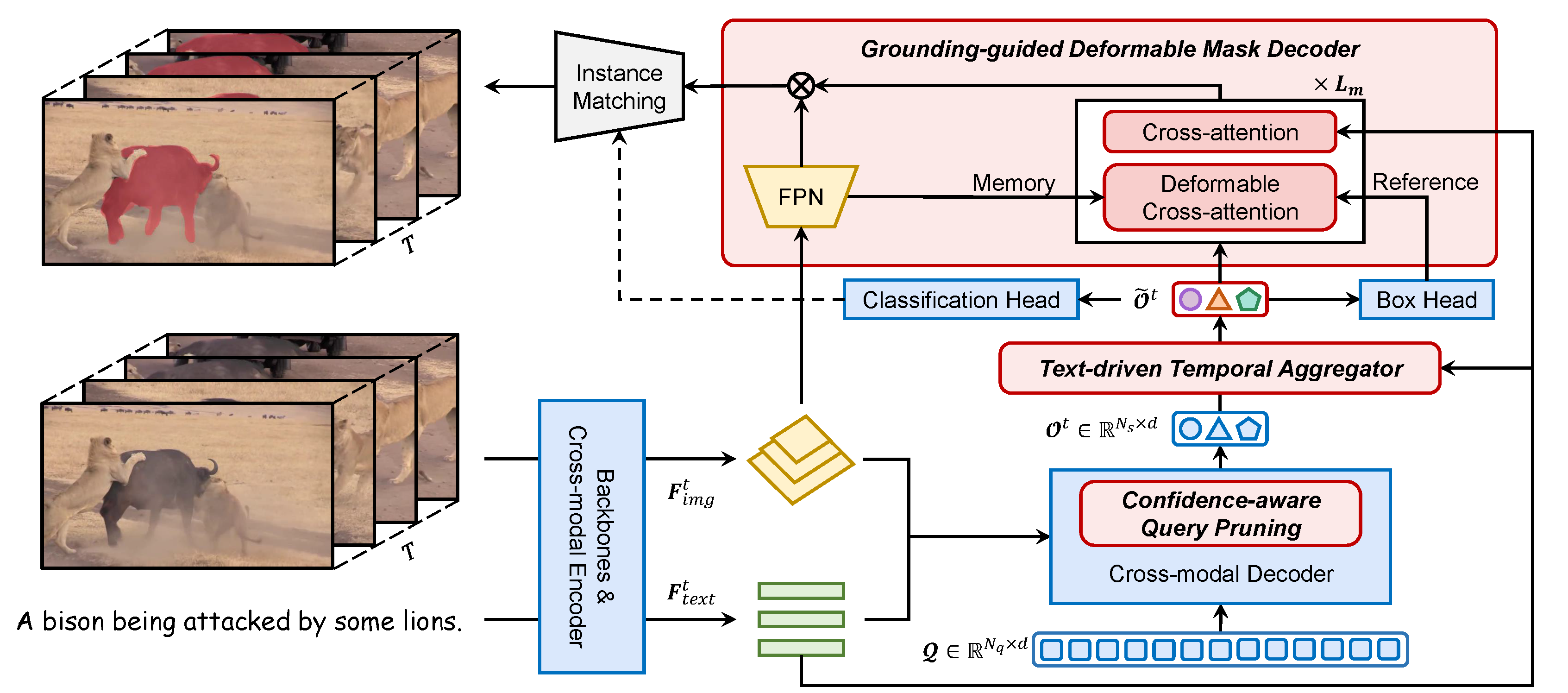
Modules colored in blue are borrowed from GroundingDINO, while those in red are newly introduced in this work.
1 Sun Yat-sen University 2 Southern University of Science and Technology
Referring video object segmentation (RVOS) aims to segment target objects throughout a video based on a text description. This is challenging as it involves deep vision-language understanding, pixel-level dense prediction and spatiotemporal reasoning. Despite notable progress in recent years, existing methods still exhibit a noticeable gap when considering all these aspects. In this work, we propose ReferDINO, a strong RVOS model that inherits region-level vision-language alignment from foundational visual grounding models, and is further endowed with pixel-level dense perception and cross-modal spatiotemporal reasoning. Experimental results on five benchmarks demonstrate that our ReferDINO significantly outperforms previous methods with real-time inference speed.
Modules colored in blue are borrowed from GroundingDINO, while those in red are newly introduced in this work.
@inproceedings{liang2025referdino,
title={ReferDINO: Referring Video Object Segmentation with Visual Grounding Foundations},
author={Liang, Tianming and Lin, Kun-Yu and Tan, Chaolei and Zhang, Jianguo and Zheng, Wei-Shi and Hu, Jian-Fang},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2025}
}